How to Structure Your Project
Software Architecture
Until recently, I hadn’t really thought about the structure of an application in much detail. I would just bootstrap an app using some kind of popular tooling and just blindly assume that whatever folder structure was generated was probably the best way of doing it.
It wasn’t until I started needing to add significantly more complex features to already complex applications that I started to notice the shortcomings of one approach over another.
This ultimately elicited the question of: What is the “best” way to structure a project? Or, in plainer terms: How should the files and directories within an application be organised?
After digging around in a few books and articles, I came to the familiar answer of: “Well, it depends.” Like most principles in Software Architecture, whether you apply a particular “solution” - and to what extent - is largely contingent on the scope of your application and whether you realistically think you’ll end up making the most of it.
Despite this, there are some generally well recognised approaches that I will attempt to distil here. In each case, I’ll provide the circumstances in which you might want to use it.
To demonstrate each approach, we’ll suppose we have a scenario of attempting to insert some kind of generic user management system into our application. We’ll require various different operations, such as being able to create, update, or delete a user. For each of these operations, we’ll simply imagine it is implemented end-to-end via a Controller (to interface with a network), a Service (to apply whatever “business” logic may be required) and a Repository (to interact with a data store, e.g., a database).
Package by Infrastructure (or layer/technology)
Package by infrastructure is both the most simple and likely the most common of the approaches. In this case, we have top-level directories that look something like the following.
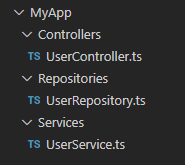
Each directory is intended to house a specific type of “infrastructure” - in this case: Controllers, Services and Repositories. This is a project structure you’ve probably seen dozens of times before. In fact, if you’ve ever started a new project using the scaffolding tools of a popular framework, this is probably very similar to what you got.
And, generally, this is fine. Distinct concepts are divided in a fairly logical way and with very little upfront effort. For smaller projects, this will be perfectly sufficient. However, as your project starts to grow larger, you may start to notice this approach doesn’t scale particularly well.
As your project starts to evolve, you can imagine how following one particular use-case (or, operation) through the system could become difficult. For example, if we wanted to investigate how a user was deleted, we’d have to hunt down the corresponding files individually within each different infrastructure folder. As long as the project remains small, this might be okay. However, as you start to implement dozens or hundreds of different features, you might notice that this starts to get out of hand, with classes that should be closely related being placed extremely far apart.
If we consider Uncle Bob’s concept of Screaming Architecture, we can see we might have a problem here. When looking at the source code of a project, we should be able to infer fairly easily what the project is actually supposed to do. Is it a shopping system? A fitness app? Perhaps a banking application? Package by infrastructure does nothing to suggest the system’s intent. Rather, it tends to just express “Laravel”, or “Rails”, which while possibly interesting, isn’t very useful. In fairness to these frameworks, it makes sense that they would scaffold projects in this way. They have no inkling of what your application is supposed to do, and they certainly have no idea what the scope is going to be. It’s only logical that they would choose to provide the simplest and least opinionated approach to start with.
Beyond poor discoverability, another issue here is that each infrastructure folder is essentially coupled to the others. Any change to the structure within an infrastructure directory needs to be replicated across all of them. Large scale refactors within a package by infrastructure system tend to be very long and arduous tasks, especially when we consider that, in a real application, we’d also probably have far more than 3 different types of “infrastructure”.
Package by Feature (or domain)
So, can we improve upon package by infrastructure at all? Well, one thing we could do is reserve a top-level spot to represent the different “features” that this application is going to implement.
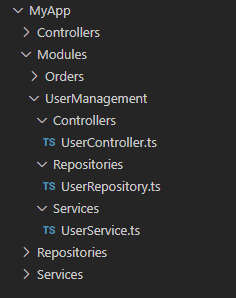
This time, we have a “Modules” folder that contains the project’s features. At first, this might look like we’ve just taken package by infrastructure and shoved it inside an inner folder. However, we note the important distinction that the infrastructure of the user management feature is separate from the infrastructure of the orders feature.
This has gone some of the way to improving the discoverability of our system. Now, when we try to follow the delete user use-case, we at least know immediately what feature to start at. We don’t have to worry about the fact that the Controllers of the user management feature are going to be intermingled with the Controllers of the orders feature. Additionally, the classes of one use-case can never be placed that far apart since we’ve at least encapsulated the functionality of one feature all in one place.
Also, note that we’re not prevented from still having top-level infrastructure directories if we really need them. I would use these sparingly, but if you truly do have generic concepts, they can be placed there.
Despite these “improvements”, on closer inspection, we might ask whether this is that much better. We realise that all we’ve really done is apply package by infrastructure on a more granular scale. The same issues that occur within package by infrastructure can simply reoccur within a particular feature’s directory. Granted, this will now take much longer to become noticeably problematic, making it beneficial still for medium-sized projects, but can we take it one step further?
Package by Use Case
The final approach can seem a little unusual at first (at least, it did to me), but for a large-scale project it might provide you with the most long-term flexibility. We’ll maintain the package by feature concept but this time we’ll group together all the source code required to implement a particular use-case.
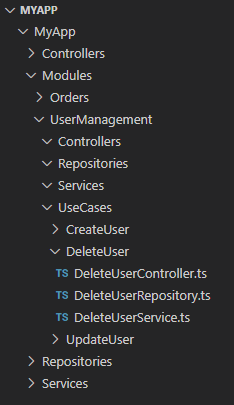
For example, in the delete user use-case we can see that we’ve grouped together the Controller, Service and Repository in to one folder that represents the use-case. In fact, at this level, we’ve removed the concept of “infrastructure” folders entirely.
Now, when we try to follow a use case, we no longer have to piece the functionality together across multiple different directories (usually spread far apart), everything is placed right next to each other. Not only that, but our architecture now “screams” not only the features it provides, but also the specific use-cases comprising those features. We don’t have to start looking inside classes to find out where a user is deleted, it’s immediately obvious from the name of the files and folders.
There are 3 other significant advantages of this approach that come to mind:
-
Our refactoring woes from package by infrastructure are now mostly alleviated, as restructuring usually just involves dragging the use cases to where you need them to be, rather than duplicating identical changes in several places.
-
By default, the Interface Segregation Principle is enforced by restricting classes to a single purpose, meaning they only depend on exactly what they need (unsurprisingly, this means it also does a pretty good job of sticking to the Single Responsibility Principle). This isn’t to suggest the other approaches can’t also respect these principles, but package by use-case prevents you from being able to ignore it.
-
An element of flexibility is provided in terms of what “type” of infrastructure we implement. Sometimes we want to create a class that doesn’t necessarily fit neatly in to being either a Controller, Service or a Repository (or any other “standard” infrastructure you use). With the first two approaches, it’s difficult to decide exactly where these classes should go. We tend to either just stick them in Services because we don’t want to think about it anymore, or create yet another top-level folder that might only get used once or twice. Package by use-case fundamentally eliminates this problem because, as we’ve seen, the infrastructure grouping concept has effectively been removed.
Conclusion
To summarise:
-
Package by infrastructure is quick and easy for small projects, but can be hard to scale.
-
Package by feature is an improvement for medium-sized projects, but is in some ways only delaying the same problems experienced by package by infrastructure.
-
Package by use-case requires the largest upfront cost, but provides good scalability and long-term flexibility for large-scale projects.
A good thing about this set of approaches is that we can see that they are built on top of one another. It may make sense to start with package by infrastructure/feature initially, then evolve as your projects start to grow and your needs become more advanced.